Recently, Mark Brookfield posted a three-part series on the process he uses for building Windows 10 images in HobbitCloud (Part 1, Part 2, Part 3). Mark has put together a great series of posts that explain the tools and the processes that he is using in his lab, and it has inspired me to revisit this topic and talk about the process and tooling I currently use in my lab and the requirements and decisions that influenced this design.
Why Automate Image Building?
Hand-building images is a time-intensive process. It is also potentially error-prone as it is easy to forget applications and specific configuration items, requiring additional work or even building new images depending on the steps that were missed. Incremental changes that are made to templates may not make it into the image building documentation, requiring additional work to update the image after it has been deployed.
Automation helps solve these challenges and provide consistent results. Once the process is nailed down, you can expect consistent results on every build. If you need to make incremental changes to the image, you can add them into your build sequence so they aren’t forgotten when building the next image.
Tools in My Build Process
When I started researching my image build process back in 2017, I was looking to find a way to save time and provide consistent results on each build. I wanted a tool that would allow me to build images with little interaction with the process on my part. But it also needed to fit into my lab. The main tools I looked at were Packer with the JetBrains vSphere plugin and Microsoft Deployment Toolkit (MDT).
While Packer is an incredible tool, I ended up selected MDT as the main tool in my process. My reason for selecting MDT has to do with NVIDIA GRID. The vSphere Plugin for Packer does not currently support provisioning machines with vGPU, so using this tool would have required manual post-deployment work.
One nice feature of MDT is that it can utilize a SQL Server database for storing details about registered machines such as the computer name, the OU where the computer object should be placed, and the task sequence to run when booting into MDT. This allows a new machine to be provisioned in a zero-touch fashion, and the database can be populated from PowerShell.
Unlike Packer, which can create and configure the virtual machine in vCenter, MDT only handles the operating system deployment. So I needed some way to create and configure the VM in vCenter with a vGPU profile. The best method of doing this is using PowerCLI. While there are no native commandlets for managing vGPUs or other Shared PCI objects in PowerCLI, there are ways to utilize vSphere extension data to add a vGPU profile to a VM.
While MDT can install applications as part of a task sequence, I wanted something a little more flexible. Typically, when a new version of an application is added, the way I had structured my task sequences required them to be updated to utilize the newer version. The reason for this is that I wasn’t using Application Groups for certain applications that were going into the image, mainly the agents that were being installed, as I wanted to control the install order and manage reboots. (Yes…I may have been using this wrong…)
I wanted to reduce my operational overhead when applications were updated so I went looking for alternatives. I ended up settling on using Chocolatey to install most of the applications in my images, with applications being hosted in a private repository running on the free edition of ProGet.
My Build Process Workflow
My build workflow consists of 7 steps with one branch. These steps are:
- Create a new VM in vCenter
- Configure VM options such as memory reservations and video RAM
- GPU Flag Only – Add a virtual GPU with the correct profile to the VM.
- Identify Task Sequence that will be used. There are different task sequences for GPU and non-GPU machines and logic in the script to create the task sequence name. Various parameters that are called when running the script help define the logic.
- Create a new computer entry in the MDT database. This includes the computer name, MAC address, task sequence name, role, and a few other variables. This step is performed in PowerShell using the MDTDB PowerShell module.
- Power on the VM. This is done using PowerCLI. The VM will PXE boot to a Windows PE environment configured to point to my MDT server.
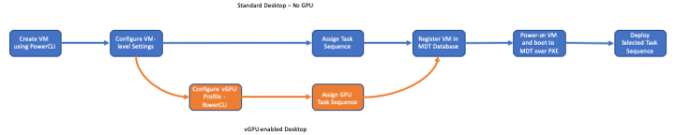
After the VM is powered on and boots to Windows PE, the rest of the process is hands off. All of the MDT prompts, such as the prompt for a computer name or the task sequence, are disabled, and the install process relies on the database for things like computer name and task sequence.
From this point forward, it takes about forty-five minutes to an hour to complete the task sequence. MDT installs Windows 10 and any drivers like the VMXNET3 driver, install Windows Updates from an internal WSUS server, installs any agents or applications, such as VMware Tools, the Horizon Agent, and the UEM DEM agent, silently runs the OSOT tool, and stamps the registry with the image build date.
Future Direction and Process Enhancements
While this process works well today, it is a bit cumbersome. Each new Windows 10 release requires a new task sequence for version control. It is also difficult to work tools like the OSDeploy PowerShell scripts by David Segura (used for slipstreaming updated into a Windows 10 WIM) into the process. While there are ways to automate MDT, I’d rather invest time in automating builds using Packer.
There are a couple of post-deployment steps that I would like to integrate into my build process as well. I would like to utilize Pester to validate the image build after it completes, and then if it passes, execute a shutdown and VM snapshot (or conversion to template) so it is ready to be consumed by Horizon. My plan is to utilize a tool like Jenkins to orchestrate the build pipeline and do something similar to the process that Mark Brookfield has laid out.
The ideal process that I am working towards will have multiple workflows to manage various aspects to the process. Some of these are:
1. A process for automatically creating updated Windows 10 ISOs with the latest Windows Updates using the OSDeploy PowerShell module.
2. A process for creating Chocolatey package updates and submitting them to my ProGet repository for applications managed by Chocolatey.
3. A process to build new images when Windows 10 or key applications (such as VMware Tools, the Horizon Agent, or NVIDIA Drivers) are updated. This process will ideally use Packer as the build tool to simplify management. The main dependency for this step is adding NVIDIA GRID support for the JetBrains Packer vSphere Plug-in.
So this is what I’m doing for image builds in my lab, and the direction I’m planning to go.



You must be logged in to post a comment.